A real life SQL optimization story
• 10 min read

Introduction
This story took place at my current job, back in late 2023. I had been working on the project for a few months when we suddenly faced a critical production issue: one of our SSIS packages went from running smoothly to taking several hours to complete, almost overnight—as if an invisible threshold had been crossed. This quickly raised concerns among the team since this package was essential for our entire data processing pipeline . Even though it still managed to finish, its drastically increased runtime was a red flag we couldn't ignore.
At that time, I was part of the specialized team responsible for optimizing legacy SQL Server data processes and migrating them progressively to Google Cloud Platform (GCP). Because of this role and my experience with performance optimization, I was quickly assigned to diagnose and resolve this critical performance issue.
As challenging as it was, this event became an unexpected opportunity to showcase my problem-solving skills—leading me to implement an optimization that reduced the package runtime by over 90%.
Initial Context and Challenges
The goal of the package was to compute a set of enriched fields concerning orders (B2C and B2B orders) into a fact table. The two more complex fields, the order's origin and the main order were defined along the same rule and had dedicated container in the SSIS package.
Let's take a look at the functional diagram of this part of the package:

Here is how to read it:
- Each node correspond to a specific condition evaluated against the order's data. It can be a simple condition like checking a simple value, or more complex ones involving multiple fields.
- When a parent node is true, the sub-conditions are evaluated in order until one of them is true. If none of the sub-conditions are true, the value given to the two fields is set to default values.
IE : if case A is true, then A.1 will be evaluated. If A.1 is false, then A.2 will be evaluated, and so on. If Case A is false, then the evaluation will directly continue with Case B.
Let's take a look at the four main cases that were evaluated in the package (A, B, C and D):

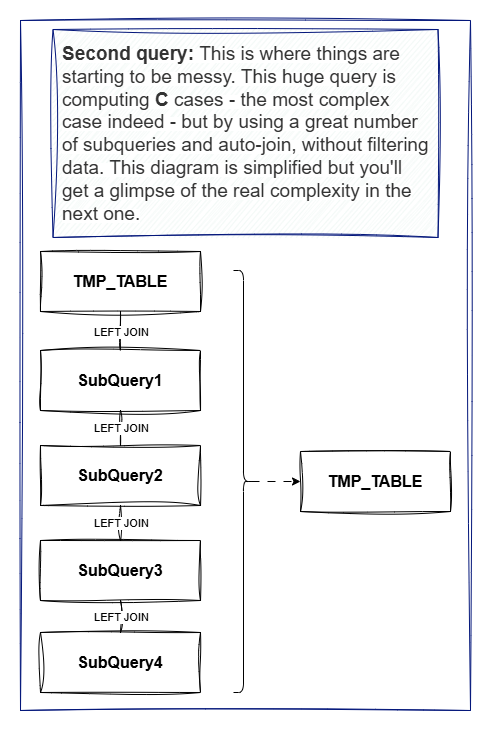
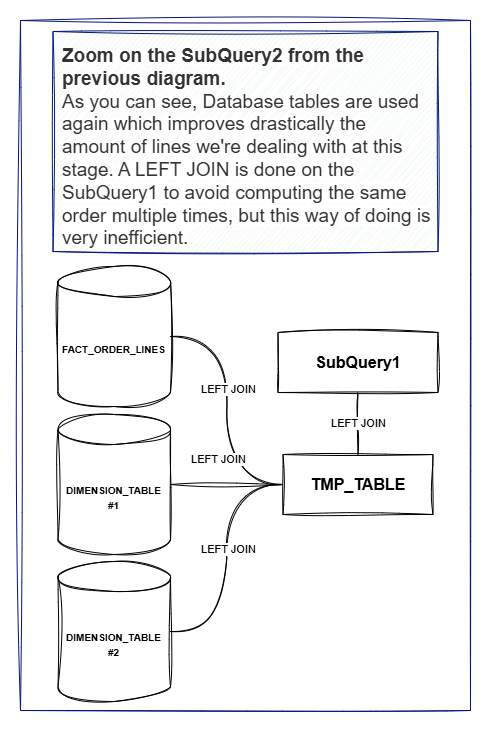
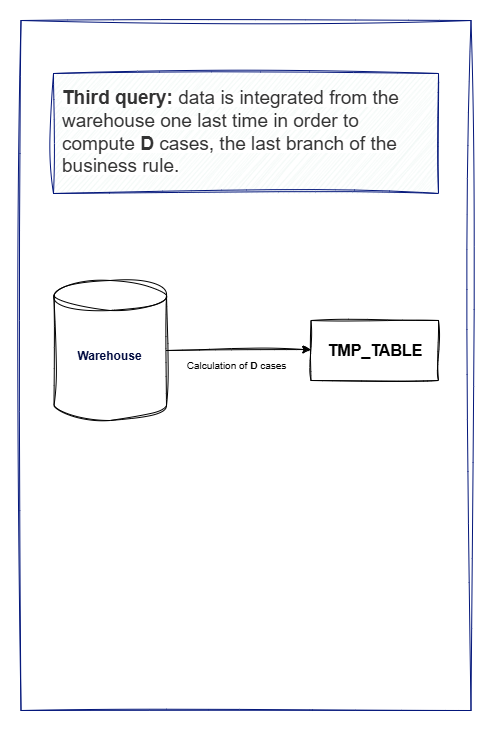
When we look at this implementation, we can see that the evaluation of the conditions is done in a very linear way, with each condition being evaluated one after the other. This means that if we have a large number of orders to process, the package will take a long time to complete, as it will have to evaluate each condition for each order.
Moreover, we always work with the entire dataset, even when some cases eare already valuated. In a temporary table, we should have only the orders that are not yet valuated. Lastly, we often use full tables from the Warehouse, which can be quite large, leading to performance issues.
Optimization ideas
Before deciding on the best optimization strategy, a good practice is to get a sense of the data we're working with. For instance, we simply looked at the volume corresponding to each case :
| Case | Percentage of dataset | Time complexity (estimate) |
|---|---|---|
| A | 26% | 15% |
| B | 29% | 15% |
| C | 8% | 55% |
| D | 37% | 15% |
Note : I no longer have access to the execution reports to display the real time complexity. The estimates are based on my observations at the time.
As you can see, A, B and D represent a significant portion of the dataset, while C is much less frequent. However, when looking at the functional diagram, the C case is the most complex one, involving multiple sub-conditions and a lot of data processing. This means that it can take a long time to evaluate, especially when we have a large number of orders to process.
Another damaging aspect of the current implementation is that it evaluates all conditions for each order, even if some conditions are already true. This means that we can end up evaluating the same condition multiple times for the same order, which can lead to performance issues. If we once again look at the functional diagram, it is clear that cases A and B have a higher priority than C and D, meaning that once an order is classified as A or B, it should not be evaluated against C and D.
This kind of thought process may seem obvious, but it is often overlooked in legacy systems where the initial implementation was done without considering the long-term performance implications, especially when the development dataset was much smaller than the production one.
Another information which is not visible in the functional diagram: A, B and D cases are rules about single orders, while C cases are rules about groups of orders. If a given order is part of a group, it will necessarily be evaluated against the C case. Yet when reading the code, single orders and groups of orders are not separated, which lead to confusion and useless evaluations.
New implementation
After analyzing the existing implementation, the functional diagram and the data, I decided to implement a new version of the package from scratch, which was'nt an easy decision to make. The production issue was critical, and we had to act quickly. However, we knew that the existing implementation was not sustainable in the long run, and that a new implementation would be more efficient and easier to maintain.
The new implementation is based on the following principles:
- Separate [A, B, D] and [C] rules: Since the C case is the most complex one but also the least frequent, we want to separate it from the other cases in order to limit the number of evaluations.
- Access to the datawarehouse tables only once: The goal is to fetch only useful data, once. The old implementation was using the same tables for each evaluation which isn't really necessary.
- Work on a limited dataset: Once an order is classified within a case, it should not be evaluated against the other cases. This is possible because of the hierarchical structure of the functional diagram. (If an order is classified as A, it will not be evaluated against B, C or D even if the conditions of those cases would be true).
Here is the new technical diagram:

Results and conclusion
The new implementation was a success: the package runtime dropped from several hours to less than 20 minutes, unblocking production and restoring confidence in the pipeline. Beyond the technical fix, this experience highlighted several best practices for optimizing data integration pipelines:
- Understand your data and processing logic: Analyze data volumes, case distributions, and the complexity of each processing step before optimizing.
- Minimize unnecessary data processing: Filter and reduce datasets as early as possible, and avoid reprocessing records that have already been handled.
- Separate simple and complex cases: Isolate rare or complex scenarios from common ones to prevent expensive operations from impacting the entire dataset.
- Limit redundant data access: Access source tables or external systems only when necessary, and reuse intermediate results where possible.
- Design for maintainability: Modular, clear logic makes future optimizations and troubleshooting easier.
These principles apply across platforms and technologies. By focusing on data flow, minimizing redundant work, and structuring logic for clarity, you can achieve robust, scalable, and efficient data pipelines.